Le Duplicate Rules consentono di definire delle regole per rilevare un (possibile) duplicato.
Una delle principali ragioni della gestione dei duplicati è il fatto di non avere una visione unica su un cliente. Se le Activity, Opportunity ecc. sono divise tra diversi record non correlati fra loro, è molto difficile avere una visione completa di quello che sta succedendo.
Esistono delle Standard Duplicate Rules presenti per: Account, Contact e Lead e possono essere create delle Custom Duplicate Rules sia per gli oggetti già citati che per tutti gli altri Custom Object.
Tutte le Duplicate Rules si trovano da Setup | Duplicate Management | Duplicate Rules:
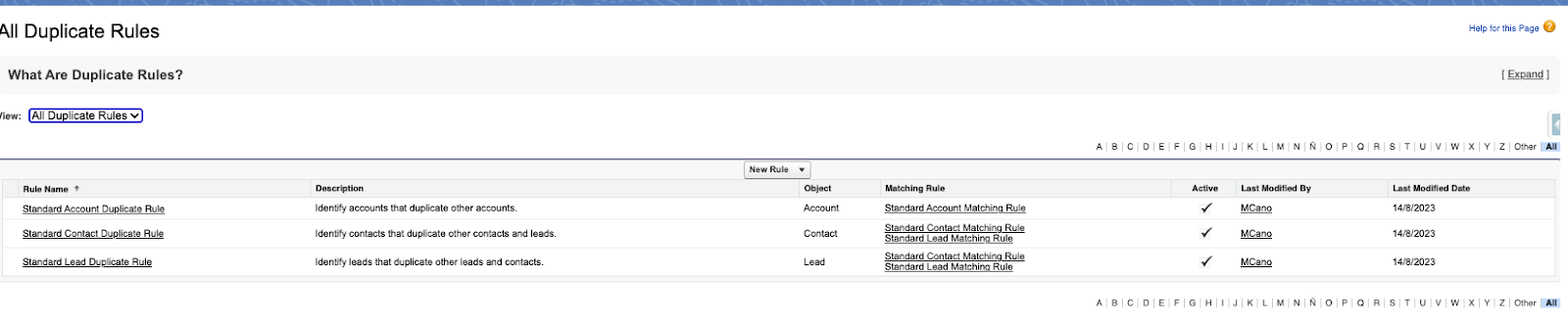
Come possiamo vedere esistono già le tre Duplicate Rules Standard che si possono modificare e disattivare ma non si possono eliminare.
Il loro comportamento è comunque uguale a quello di tutte le altre Duplicate Rules.
Creare una Duplicate Rules
Per creare una Duplicate Rules basta cliccare su “New Rule” e selezionare l’oggetto:
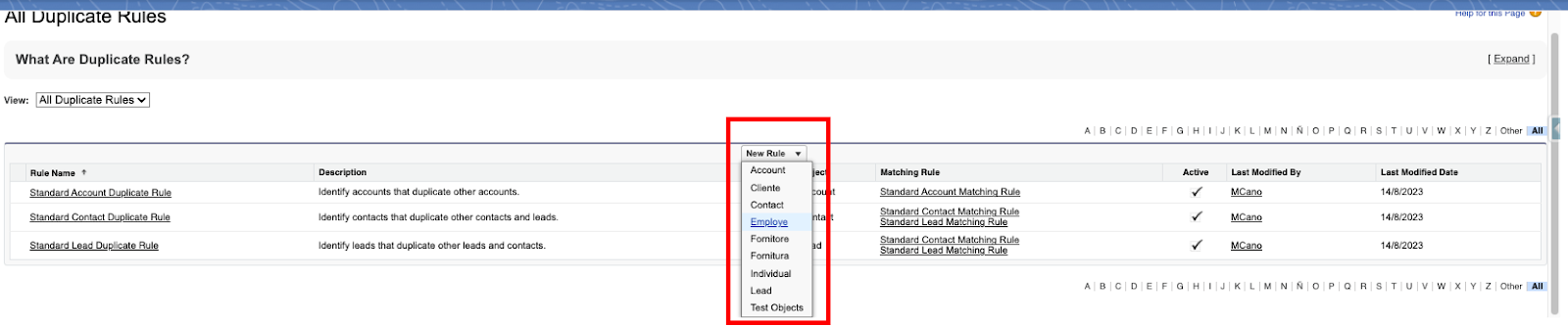
Una volta cliccato su New si aprirà una form composta da quattro sezioni:
- Rule Details: inserire nome, descrizione e se si vuole o no forzare le sharing rules, ovvero se si vuole che la Rule prenda in considerazione tutti i record possibili duplicati o soltanto quelli a cui un utente ha accesso.
- Duplicate Rules: in questa sezione si specifica cosa può fare l’utente una volta che si è trovato un duplicato: se consentire comunque la creazione/modifica del record oppure no.
La scelta più restrittiva o meno restrittiva dipende soprattutto dal Business e dalle condizioni in cui si trova il Database di partenza. - Matching Rules: questa sezione risponde alla domanda “che cosa deve essere considerato un duplicato?”. Si sceglie una diversa matching rule (creata in precedenza) e anche il record di quale oggetto con il quale confrontare il duplicato.
- Conditions: questa ultima parte consente di scegliere se le Duplicate Rules si devono attivare per tutti gli utenti o se soltanto per alcuni tipi (magari in base al profilo dell’utente, alla fonte del record e cosí via).
Creare una Duplicate Rule non è molto difficile, è importante definire bene le azioni previste e soprattutto definire con regole precise cosa rappresenta un duplicato. Perché le ripercussioni sul Business e anche sul tipo di lavoro che effettuano gli agenti può essere semplificato (o complicato) di molto.
Definire le Matching Rules
Una Matching rules si puó creare direttamente dalla schermata di creazione della Duplicate Rule, nella sezione Matching Rules:
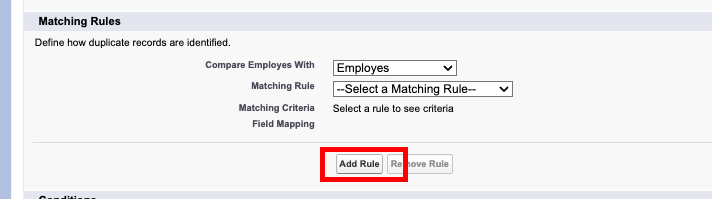
Oppure da Setup | Duplicate Management | Matching Rules e cliccando su New:

Una volta cliccato su “New” si dovrà scegliere l’oggetto per cui creare la Matching rule, premere Next e poi ci si troverà la schermata di creazione vera e propria:
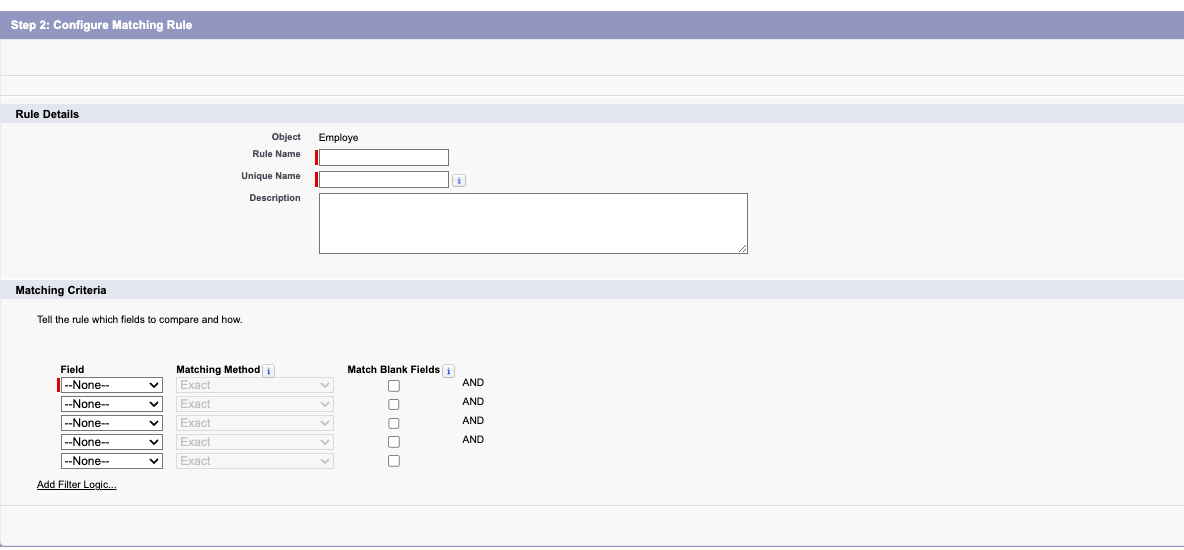
Bisognerá inserire nome e descrizione, nonché i criteri per cui si considera un un elemento duplicato: per esempio potremmo identificare un Contact come duplicato se ha lo stesso numero di telefono, o la stessa email, o un nome molto simile.
Possiamo scegliere diversi campi e scegliere due tipi di Matching method:
- Exact: quindi se i due campi dei due record coincidono esattamente
- Fuzzy: ovvero se due campi sono molto simili. L’algoritmo Fuzzy ha diverse varianti ed è disponibile soltanto per alcuni tipi di campo: non è per esempio disponibile per il campo di tipo “Email” ecc. Tipi di Fuzzy:
- Fuzzy: Firstname: utilizza diversi algoritmi per calcolare la “distanza” fra un nome ed un altro: Exact, Initials. Jaro-Winkler, Name Variant.
- Fuzzy LastName: gli algoritmi per calcolare la distanza sono: Exact, Keyboard distance, Metaphone 3.
- Fuzzy: Company Name: toglie alcuni valori dal nome se presenti (In, Group ecc) e gli acronimi vengono normalizzati. Dopodichè di utilizzano i seguenti algoritmi: Acronym, Exact, syllable Alignment.
- Fuzzy: Phone: I numeri sono divisi in sezioni e ogni sezione viene confrontata. Ogni seziona utilizza un metodo diverso.
- Fuzzy: City: gli algoritmi usati sono Edit Distance e Exact.
- Fuzzy: Street: viene utilizzato l’algoritmo Exact sempre con lo stesso metodo del Phone, la stringa viene suddivisa in sezioni e ogni sezione comparata.
- Fuzzy: Zip: algoritmo utilizzato: Weighted Average.
- Fuzzy:Title: algoritmi utilizzati per calcolare la distanza: Acronym, exact, Kullback-Lieber e Distance.
Anche se ho elencato tutti i tipi di algoritmi utilizzati per calcolare la “distanza” fra due stringhe e capire se esse sono uguali o no, nella maggior parte dei casi non sarà necessario conoscere come funzionano in particolare. Basterà utilizzare l’algoritmo con il relativo campo: se vogliamo confrontare due cognomi, utilizzeremo il fuzzy: LastName ecc.
Non tutti questi algoritmi non sono disponibili per tutti i tipi di campo: se un campo è di tipo Phone, avrò a disposizione soltanto il metodo “Exact” (disponibile per tutti i tipi di campo) e fuzzy: Phone.
L’eccezione può avvenire quando vogliamo confrontare un campo di tipo testo che non rappresenta una informazione per cui esiste il relativo algoritmo fuzzy: in questo caso si che sarà necessario capire quale algoritmo è quello necessario nel nostro caso!
Conclusioni
Come molti strumenti di automazione, creare delle duplicate rule non è troppo complicato. Però sì che le conseguenze delle azioni possono essere molto complesse: è necessario quindi, stabilire con estrema chiarezza quello che ci si aspetta (in questo caso) dalle duplicate rule e quali sono le azioni che gli agenti dovranno poi effettuare.
0 commenti